

Monitorizare & Observabilitate pentru rețele și infrastructură
Vizibilitate unificată, alerte utile și rapoarte clare. Identificăm degradările înainte să devină întreruperi și vă oferim tablouri de bord simple pentru decizii rapide.
Potrivit pentru
- Rețele multi-site (HQ + filiale, depozite, magazine)
- Ambiente cu SLA strict (call center, producție, logistică)
- Echipe IT mici care au nevoie de vizibilitate fără zgomot
- Organizații care vor rapoarte executive lunare, nu loguri brute
Ce obțineți concret
- Alerte care contează (Teams/email) cu context și pași de remediere
- Dashboarduri Grafana pe categorii: WAN/LAN, Wi-Fi, servere, securitate
- Rapoarte executive: disponibilitate, top incidente, tendințe capacitate
- Runbook-uri pentru incidente repetabile (cine, ce, în ce ordine)
- Istoric pentru analiză post-incident și planificare capacitate
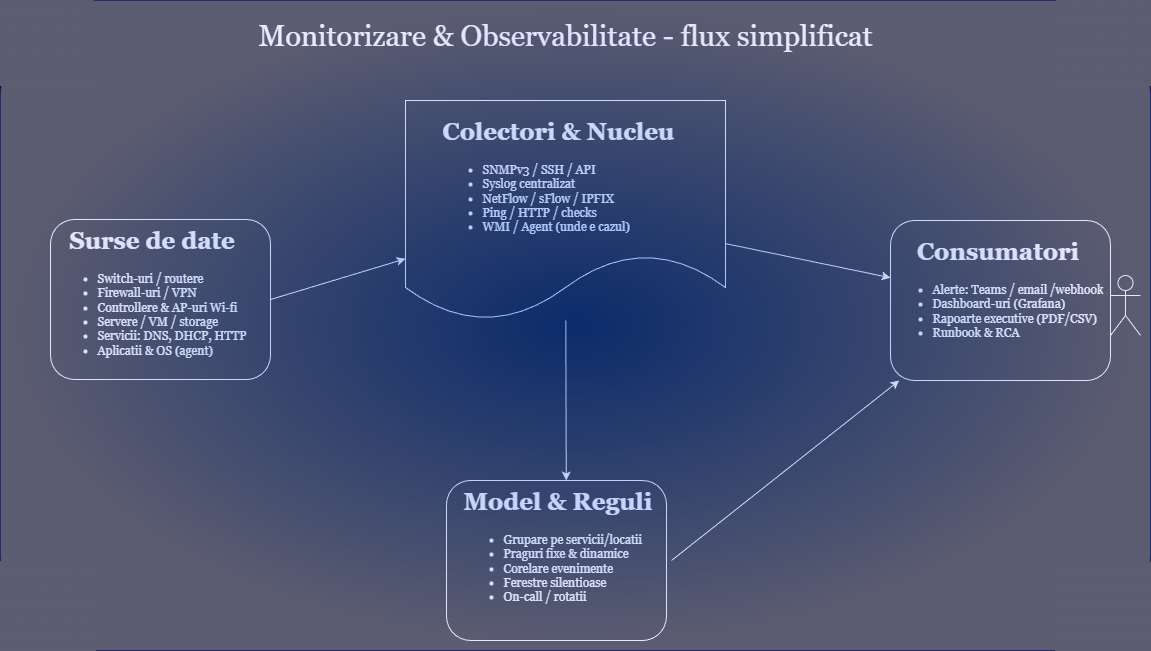
Metodologie în 6 pași
- Inventariere: listă echipamente, versiuni, locații, priorități.
- Colectare: SNMP/SSH/API, NetFlow/sFlow, syslog, ping/HTTP, WMI/agent acolo unde e necesar.
- Model & praguri: grupăm pe servicii și locații, definim praguri fixe/dinamice și corelări.
- Dashboarduri: tablouri dedicate (rețea, Wi-Fi, securitate, servere), executive overview.
- Alertare: reguli pe severitate, agregare, ferestre silențioase, on-call.
- Rapoarte & îmbunătățire: trenduri, RCA, optimizări trimestriale.
Timp estimat & implicare
- Setup nucleu: 0,5–1 zi (server de monitorizare, acces rețea, conturi read-only).
- Integrare echipamente: 1–3 zile (profiluri SNMP, colectori NetFlow, syslog, agenți unde e cazul).
- Dashboarduri & alerte: 1–2 zile (modele, praguri, Teams/email, test load).
- Rapoarte & runbook: 0,5–1 zi (format lunar, KPI, proceduri incident).
Cerințe: acces read-only (SNMPv3, API), feed NetFlow/sFlow, syslog centralizat, cont service AD (dacă e necesar), persoană de contact IT pentru fiecare locație.
Întreruperi: colectarea este pasivă; nu afectează traficul. Configurările pe echipamente se fac în ferestre planificate.
Echipamente & surse suportate
- Switch-uri/routere, firewalls, controlere Wi-Fi și AP-uri
- Servere fizice/VM, hipervizoare, stocare, servicii critice (DNS/DHCP)
- Colectare: SNMPv3, syslog, NetFlow/sFlow/IPFIX, API/SSH, WMI/agent
- Vizualizare: Grafana, tablouri custom pe roluri (IT, management)
- Integrare notificări: Microsoft Teams, email, webhook
Lucrăm cu ce aveți sau propunem alternative care se potrivesc bugetului și cerințelor.
Exemple de scenarii & recomandări
| Scenariu | Provocare | Recomandare pe scurt |
|---|---|---|
| Link WAN saturat | Viteză mică, latență mare | NetFlow + praguri pe utilizare; QoS și program pentru trafic non-critic; raport capacitate |
| AP-uri cu clienți mulți | Degradare Wi-Fi la ore de vârf | Alertă pe număr clienți/AP și retry rate; balansare încărcare; ajustare canale/puteri |
| Tunel VPN instabil | Intermitențe între sedii | Monitorizare SLA tunel; corelare cu evenimente ISP; fallback și alerte graduale |
| Server aplicație lent | Utilizatori afectați | Corelare CPU/memorie/disk I/O cu latență; praguri dinamice; runbook de scalare |
| Certificat aproape expirat | Servicii ar putea cădea | Scan programat; alertă la 30/14/7 zile; procedură de reînnoire |
| Loguri copleșitoare | Zgomot, lipsă semnificație | Filtrare pe severitate/sursă; reguli de agregare; alerte doar pe anomalii |
Ce livrăm
- Instanță de monitorizare configurată și securizată
- Dashboarduri pe servicii/locații + overview executiv
- Politici de alertare și integrare Teams/email
- Runbook-uri pentru incidente frecvente
- Raport lunar: disponibilitate, incidente, recomandări
Studii de caz și pașii următori
Vedeți proiectele livrate. Pentru o estimare, trimiteți lista echipamentelor și locațiilor; revenim cu un plan clar.